Scaling into the Terabytes
This post is about where Saito is in terms of blockchain scaling, the technical challenges that we face and our roadmap for processing even larger amounts of data moving forward. If you’re technically-minded and interested in on-chain blockchain scaling, please get in touch!
So, where are we? Our team is in the final stages of preparing for our Eames Testnet, which will run on our first software release theoretically capable of supporting terabyte-level scale. What this means is that the core operations needed for blockchain processing run quickly enough on laptop-grade hardware for nodes to follow a chain of blocks spaced thirty seconds apart where each block is limited to a maximum of 10,000 transactions or 350 MB of data. As unlike in other networks which focus exclusively on TPS, in Saito-class networks both transaction volume and size matters as the goal is to allow the inclusion of arbitrary data directly on-chain. This affects performance as things like string-length restrictions are suddenly limiting factors and some optimizations are not possible because the size of transactions cannot be hardcoded.
To share raw performance numbers, a 65 MB block with 100,000 transactions takes about 16 seconds to add to the blockchain. A larger 350 MB block with only 10,000 transactions takes around 6 seconds to process. Meanwhile, a tiny 6.5 MB block with 10,000 transactions takes a bit over a second. Anyone can replicate these figures by downloading our source code and playing around with it: contact us and we’ll walk you through configuring the tests. As our experiments show, the slowest part of the code is the part that deals with validating transactions, a process that requires hashing transaction data and then validating that those hashes have been properly signed by the sender of the transaction.
What is left out of these figures is the time needed to download and propagate blocks, handle rebroadcast transactions (which slows things down as it requires heavy disk access) and/or updating wallets. We are also not counting the time needed to generate transactions, for instance, as we expect transactions to be generated organically by peers on the edges of the network. Nor is this a guarantee that the software will achieve these speeds in a production environment. Long-term chain reorganizations can currently result in thrashing if the system needs to reorganize long-chains of blocks. We aren’t that fussed about these omissions though because most of these have significant margins-for-error and potential problems can be mitigated or optimized moving forward.
In all cases, the good news is that Saito’s memory consumption appears stable: rising gradually until the necessary number of blocks are stored in memory and then flatlining as old data starts being purged from the blockchain to make room for new blocks and new transactions.
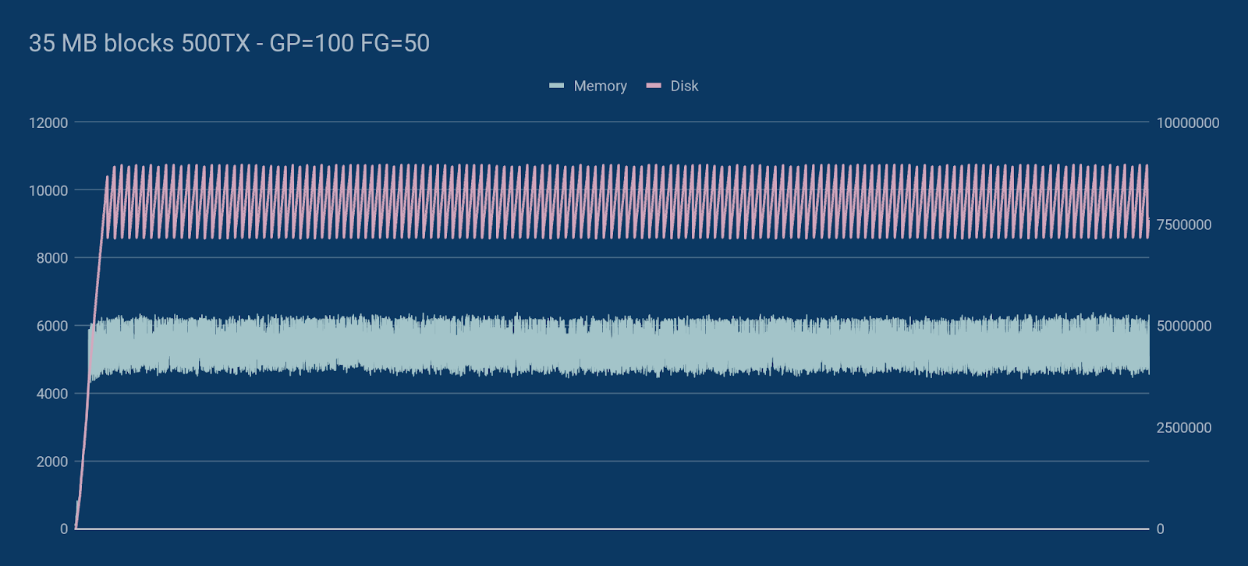
We’re pleased with this data because it shows an upper-bound to memory consumption and suggests obvious ways to increase throughput that are on our agenda for the next core release. One of the most obvious steps, while we will continue to support this NodeJS version as our official lite-client, we will be moving to another languages that has support for multi-threading and shared memory management for the next core routing client.
In terms of overall technical design, one of our biggest wins has been using Google Dense Hash Maps to store our UTXO commitment set. Even with fairly massive blocks with hundreds of thousands of transactions, using in-memory data structures to track whether slips are spendable has made validating inputs blazingly fast. Of note, Saito’s transient chain works perfectly with this approach as it eliminates the need to plan for an eternally-growing blockchain and for the periodic resizing of the hashmap. Avoiding a reliance on files is also something we need to improve as the time-delays involved in disk access becomes significant as blocks stretch towards the GB level and transaction rebroadcasting becomes essential at scale.
Beyond our single-threaded architecture and delays imposed by disk access, the third biggest factor limiting Saito’s performance comes from its reliance on JSON as the default serialization method. JSON is slow to write to disk as it involves a lot of string concatenation and of course results in a block that is far larger than needed. And JSON is even slower to parse back into a useable object. In-house tests show that this is the slowest part of the codebase. As such, while we will continue to use JSON to send blocks to lite-clients, we will introduce a binary block format in the next version of Saito that will make data read/writes far more efficient. I’d estimate that we’re about five months from having this implemented, at which time we will shift from the Eames Testnet to what comes next.
Another benefit of faster read/writes and a binary file format is that shared memory and a multi-threaded architecture can be used to speed up block creation and validation. In terms of the time needed to validate transactions, the two most time-consuming parts of the process involve (1) hashing transactions and (2) verifying signatures. These processes are computationally intensive, and while we are able to do some rudimentary clustering in NodeJS to speed up signature validation, doing this requires creating bottlenecks in other ways (such as sending significant data through OS-level pipes).
Because of this, in the next version of Saito we will be focused on low-level parallel processing: making transaction hashing something that can be handled in parallel along with signature verification, and with minimal needs for communications between processes. Blocks will need faster ways of being pushed into memory and access to them will be shared between threads. We believe these steps will allow transaction throughput to scale essentially linearly to the number and speed of CPU cores on core machines. On the off-chance you are reading this and find this sort of optimization work fascinating, come and join us in Beijing.
Given all of the above, our goal for overall scaling is to aim for a tenfold increase in software throughput in the next year by shifting to a lower-level language and improving the way our core software manages in-memory data and reads and writes files to disk. Once we hit limits of actual software processing, we expect to be able to secure another order of magnitude through the application of high-grade hardware. The long-term goal is bringing the capabilities of the software close to handling the amount of data we believe it is possible for a high-throughput server to handle in a high-quality data centre with the ability to offer 100 TBPS connections to remote peers on backbone network infrastructure. And what about bandwidth requirements and block distribution times?
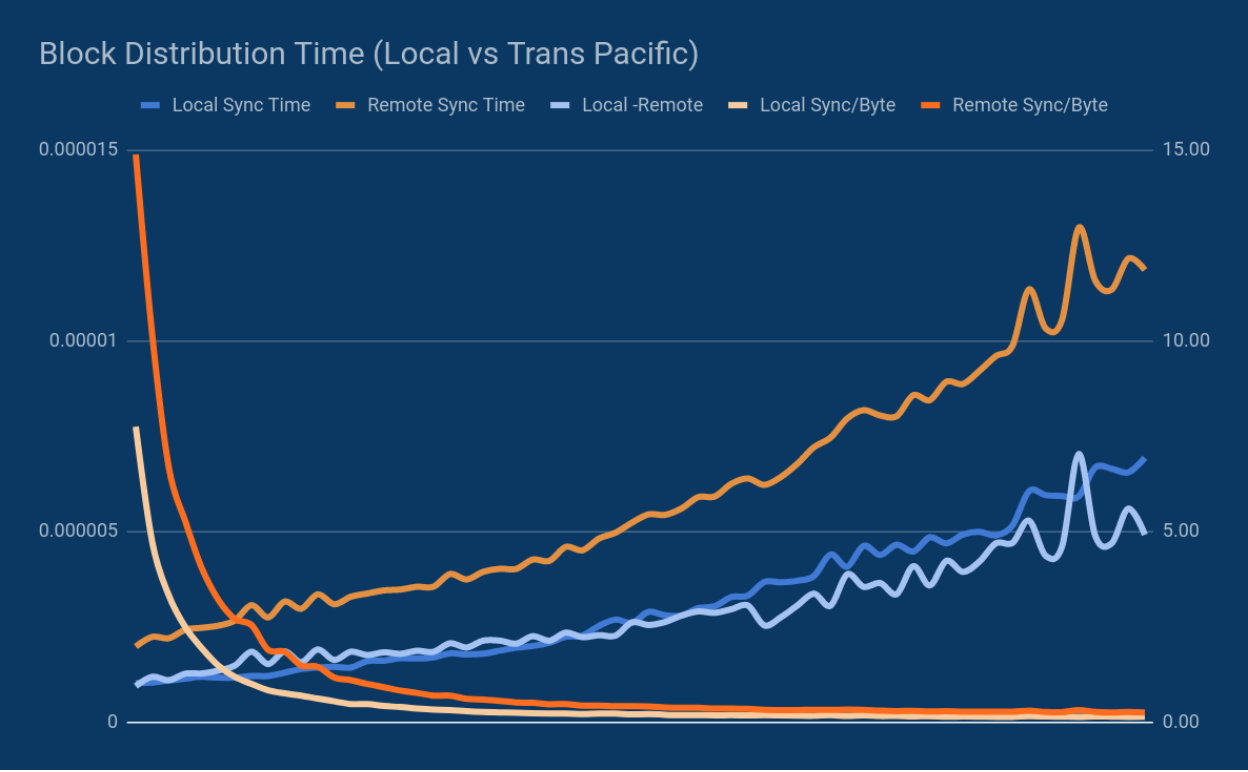
As this last point gets us to the question of network throughput, we would be remiss not to point out that network capacity issues are obviously the largest limiting factor in the short-term. Although Saito does not require the universal broadcast of transactions in the same way that networks like Ethereum and Bitcoin do (we do not take for granted that nodes are or should be incentivized to propagate transactions if they are not compensated for the work), network bandwidth will still be a limiting factor on budget machines for the foreseeable future if only because most cloud computing systems have limits on burst capacity, with “guarantees” of performance often peaking around 25 MBPS.
In our tests to date, when our test servers are running on commodity cloud-computing platforms like Amazon and Digital Ocean, the practical limit for trans-Pacific data transfers (the slowest “single hop” in the world) is about 300 MB per minute. Experiments incline us to believe we can improve this to 750 MB per minute, but this will require significant changes to how Saito handles data distribution (i.e. not just a single thread forwarding files).
With that said, while network capacity restrictions suggest that the total throughput of a global Saito network should be kept under 1 TB (particularly to keep the network safe in the event of chain reorganizations and flooding attacks), we do not view network throughput as a hard limitation. As those familiar with Saito know, the revenue in our blockchain that would otherwise go to miners or stakers in other systems goes directly to routing nodes in the Saito network: it is routing activity that actually secures the network in Saito. This will permit the core network to pay for the high-capacity pipelines needed and even incentivize the deployment of high-throughput fibre-optic cables. Instead of expensive mining facilities operating in rural Sichuan, Saito will fund the expansion of the Internet’s data infrastructure. Scaling issues can also be avoided through the deployment of regional Saito networks that keep most data circulating around high-throughput national networks.